As we approach the exascale era in high-performance computing, the need for innovative algorithms that can efficiently handle massive datasets and complex computations is increasing. The CBM4scale innovation study focuses on the development of a novel matrix compression format and associated algorithms to improve the performance of Graph Neural Networks (GNNs) and other scientific applications on exascale systems.
In a recent interview, Prof. Dr. Siegfried Benkner, co-principal investigator of CBM4scale and head of the Scientific Computing Research Group at the University of Vienna, provided an overview of the study’s goals, the challenges of exascale computing, and how the CBM4scale innovations could revolutionize the field of artificial intelligence (AI) and HPC.
The Motivation Behind CBM4scale
At its core, CBM4scale is designed to optimize a fundamental data structure that is critical to many scientific and machine learning applications. According to Dr. Benkner, the primary goal is “to optimize a basic data structure that is used in many scientific applications in a way that can lead to more computational and energy efficiency.” CBM4scale focuses specifically on binary matrices, which are critical to the operation of GNNs – a class of machine learning models that are increasingly seen as driving future AI development.
Graph Neural Networks (GNNs) operate on graph-structured data, which can represent relationships and interactions between entities in domains such as social networks, biology, chemistry, and natural language processing. As these datasets grow in size, particularly in the context of exascale supercomputers, managing and processing them efficiently becomes a significant challenge. Benkner mentions that “high-performance computing is now an enabling technology for artificial intelligence” and GNNs are among the most demanding applications when it comes to computational resources.
Why Graph Neural Networks?
The decision to focus on GNNs is driven by their potential in exascale computing. These machine learning models are designed to learn from graph-structured data, where nodes represent entities and edges capture relationships. GNNs can be applied to a wide range of applications, including social network analysis, recommender systems, and drug discovery. However, as Benkner points out, GNNs are resource-intensive: “These graphs can become very, very large, and if you have graphs of extreme size, you also need very powerful computer systems.”
The studies’ emphasis on GNNs stems from their significance in AI-driven scientific applications, where the ability to handle and compute on large graphs is critical. This is particularly true for applications running on exascale systems, which are capable of performing over a billion x billion (=1018)calculations per second. However, to fully utilize the power of exascale computing, significant innovations in algorithm design and data structure optimization are required. These are challenges that CBM4scale aims to address.
The CBM Format: A New Era for Binary Matrix Compression
At the heart of the CBM4scale project is the development of the Compressed Binary Matrix (CBM) format, a new algorithm designed to optimize the storage and manipulation of binary matrices. Binary matrices, which consist only of 0s and 1s, are commonly used in both scientific computing and machine learning. However, existing methods for representing and computing with these matrices, such as the COO (Coordinate Format) and CSR (Compressed Sparse Row) formats, are not as efficient as one might think.
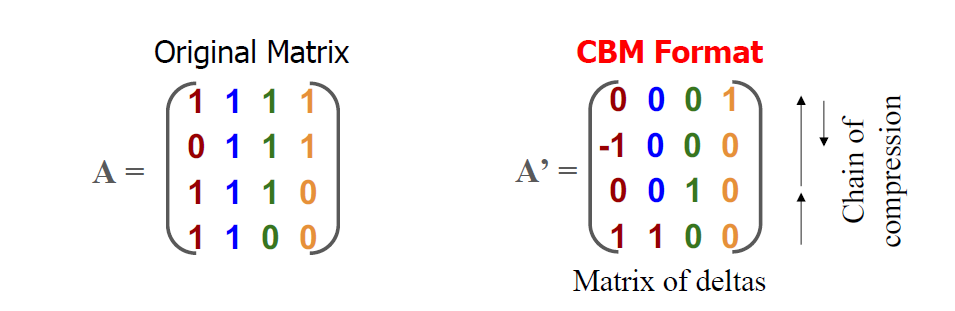
CBM4scale introduces a radically different approach by applying differential compression to binary matrices. Traditional sparse storage formats, such as CSR, focus on storing only the non-zero values in a matrix, but this approach can still lead to inefficiencies when dealing with large, sparse matrices. Instead, the CBM format exploits row similarities within the matrix by storing only the differences (deltas) between rows. As Benkner explains, “Our method uses only 1/10 of the data compared to traditional formats for certain datasets.”
This differential compression significantly reduces memory requirements and increases computational speed. In practical terms, this means that the CBM format can store a matrix more compactly, requiring less memory bandwidth and reducing the time needed to load the matrix into memory during computation. This results in faster processing times and reduces memory usage and energy consumption.
The Core Algorithm: Compressed Binary Matrix Muiply (CBMM)
The efficiency of the CBM format extends to its Compressed Binary Matrix Multiply (CBMM) kernel, a novel algorithm designed to perform matrix multiplication on compressed matrices. In traditional matrix multiplication, each element of one matrix is multiplied with the corresponding element of another matrix. While this is computationally expensive, CBMM optimizes the process by exploiting the compressed structure of CBM matrices, reducing the number of computations required.
The CBMM kernel also makes use of row-wise-reuse, a concept that exploits the similarities between rows. When multiplying two matrices, the CBMM kernel reuses previously computed dot products between similar rows, thus reducing the number of calculations. Benkner notes, “The core concept is differential compression, where we represent each row only by means of the differences with one reference row, and this significantly reduces the number of operations.”
The improvement is not just theoretical. Initial tests of the CBM and CBMM algorithms have shown compression rates of up to 10 timesfor certain datasets, such as citation networks, and performance gains of 2 to 3 times in computational speed when compared to traditional sparse matrix formats such as CSR and COO.
Overcoming the Challenges of Exascale Computing
Exascale systems present unique challenges in terms of scalability and computational efficiency. While these systems are designed to deliver unprecedented levels of computing power, the reality is that many current applications do not fully exploit this potential. One of the key obstacles is data locality. This refers to the ability to access data efficiently across the many distributed nodes of an exascale system.
The CBM format, with its reduced memory footprint, offers a solution to this problem by minimizing the amount of data that needs to be transferred between nodes during computation. Benkner explains that “by improving data locality and reducing the need for inter-node communication, the CBM format allows applications to scale more effectively across the large, distributed memory architectures of exascale systems.”
In addition, CBM4scale targets the inherent parallelism challenges of exascale systems. The CBMM kernel is designed to exploit task-level as well as data-level parallelism, meaning that computations can be distributed across multiple processors – both CPUs and GPUs – in a way that maximizes efficiency. This is particularly important in heterogeneous computing environments, where different types of processors are used for different tasks. By efficiently balancing these tasks, CBM4scale ensures that each processor is used to its full potential.
A Greener Future for High-Performance Computing
One of the benefits of CBM4scale is to reduce the energy consumption of HPC applications. As supercomputers continue to grow in size and complexity, their power requirements have become a concern. The world’s fastest supercomputers now consume tens of megawatts of power, costing millions of Euros in electricity each year. As Benkner puts it, “The fastest systems at the moment consume around 20 MW of power – equivalent to roughly €20 million of electricity just to run the machine.”
The CBM format addresses this problem by reducing the memory and computational requirements of large-scale machine learning applications such as GNNs. By compressing binary matrices and reducing the number of operations required for matrix multiplication, CBM4scale helps to reduce energy consumption, making HPC systems more sustainable and environmentally friendly. This is an important development in a field where reducing the carbon footprint is becoming as important as improving performance.
CBM4scale in the Scientific Community
Looking ahead, the CBM4scale project aims to integrate its innovations into the PyTorch Geometric (PyG) framework, one of the most widely used open-source libraries for GNNs. This will make the CBM and CBMM algorithms available to a broad user base, including scientists and developers working on HPC and machine learning applications. This will allow the broader scientific community to benefit from the performance and energy efficiency improvements that CBM4scale brings.
The potential impact of CBM4scale extends beyond GNNs. Benkner sees applications in fields ranging from computational biology and drug design to finance and energy systems. Graphs are a versatile way to represent complex systems, and the innovations developed in CBM4scale could be applied to a wide variety of fields. “We hope that we can have an impact on one or more of these many application scenarios,” says Benkner, emphasizing the broad applicability possibilities of CBM4scale’s methods.
The Importance of Collaboration
One of the strengths of CBM4scale is the collaboration between INESC-ID Lisbon and the University of Vienna, two institutions with complementary expertise. While the Lisbon team brings deep experience in algorithm development and optimization, the Vienna group contributes cutting-edge knowledge in parallel programming models and HPC systems. This collaboration has been instrumental in pushing the boundaries of what’s possible in algorithm design and real-world application.
Benkner emphasizes the importance of interdisciplinary collaboration, noting that “in today’s complex world, you need interdisciplinary teams to achieve breakthroughs.”